 Computer Systems
Computer Systems
Compilers · Computer Architecture · Operating Systems · Databases
Overview
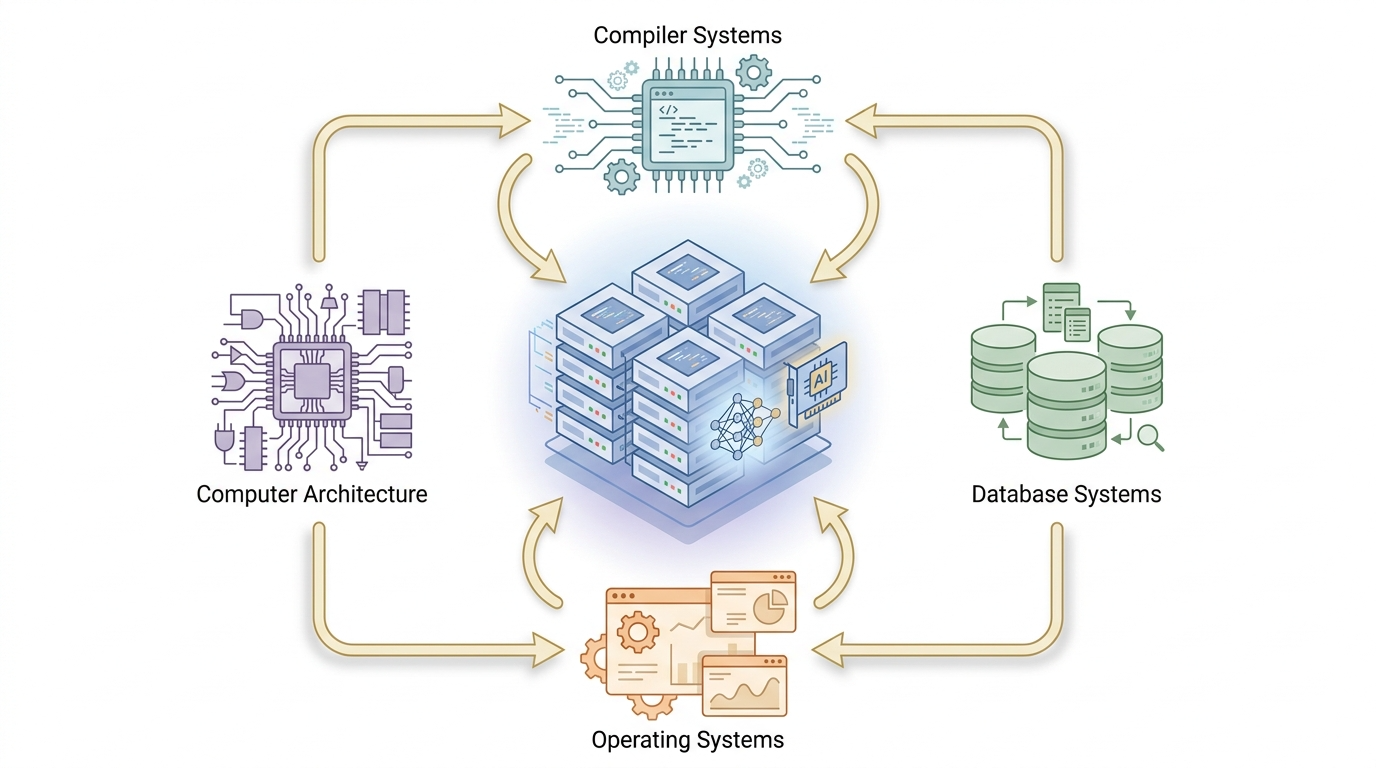
Computer systems research investigates how the layers between a user's program and the physical machine — compilers, architecture, operating systems, and databases — fit together to determine performance, correctness, and energy. These four pillars are usually taught separately, but in practice they constantly interact: a compiler optimization that ignores the memory hierarchy is wasted; a database engine that ignores OS-level I/O scheduling cannot meet its latency targets; a CPU pipeline that does not anticipate the kind of code modern compilers emit will idle under real workloads.
My interest in this thread comes from one observation — every other research area I work on (AI security, federated learning, quantum, medical AI, autonomous driving) ultimately runs on a stack of systems software. Understanding that stack deeply is what turns a model on paper into a system that actually works in the world.
1. Compilers
Compilers are the bridge between high-level program intent and the physical hardware that executes it. My work spans four complementary directions of compiler technology:
- AI / ML Compilers — graph-level optimization passes for deep learning models (TVM, XLA, MLIR), operator fusion, layout transformation, kernel scheduling, and autotuning to extract maximum throughput from accelerators.
- Hardware-aware Compilation — lowering computational graphs onto FPGAs, GPUs, and emerging NPUs, with explicit modeling of memory hierarchies, dataflow patterns, and polyhedral loop transformations.
- Quantum Compilers — circuit optimization, gate decomposition, qubit routing, and noise-aware transpilation that adapts logical quantum circuits to real NISQ devices.
- Classical Compiler & PL Theory — LLVM-based static analysis, SSA transformations, and formal semantics that make optimizations provably correct.
2. Computer Architecture
Computer architecture studies the design and behavior of the processor itself — pipelines, caches, memory systems, and the parallelism available across cores and accelerators. Even modest workload optimizations only pay off if the underlying machine actually delivers what its instruction set advertises.
- Memory hierarchy and cache behavior — cache-aware data structures, blocking, and prefetching strategies that exploit temporal and spatial locality.
- Instruction-level and thread-level parallelism — out-of-order execution, branch prediction, SIMD vector units, and multi-core / multi-socket scaling.
- Accelerator architectures — GPUs (warps, tensor cores), TPUs (systolic arrays), NPUs, and how their execution models shape software design.
- Energy- and reliability-aware architecture — DVFS, approximate computing, and resilience to soft errors / bit-flips — directly relevant to AI security research on fault injection.
3. Operating Systems
The operating system is the layer that turns a piece of physical hardware into a programmable platform — managing processes, memory, files, and network I/O, and providing the isolation guarantees that everything above it depends on.
- Process and thread scheduling — CFS, real-time schedulers, and how scheduling decisions show up as latency variance in user-space workloads.
- Virtual memory and address translation — page tables, TLBs, huge pages, and the cost of memory mapping for large model weights.
- File systems and I/O — block layer, page cache, I/O schedulers, and modern storage stacks (NVMe, io_uring) that matter when reading TB-scale datasets.
- Virtualization and containers — KVM, namespaces, cgroups, and the OS primitives behind every modern ML training cluster.
- Kernel security — privilege separation, SMAP / SMEP, and side-channel mitigations — overlapping with my AI security work on adversarial robustness.
4. Databases
Database research sits at the intersection of algorithms, systems, and storage. Modern AI workloads have made databases doubly important: training data pipelines, vector search, and online inference all increasingly look like database problems.
- Query processing and optimization — relational algebra, cost-based optimizers, join algorithms, and adaptive query execution.
- Transactions and consistency — ACID, MVCC, isolation levels, and distributed consensus (Paxos / Raft).
- Storage engines — B+ trees, LSM-trees, columnar storage, compression, and how storage layout determines query performance.
- Vector and ML-native databases — approximate nearest-neighbor indexes (HNSW, IVF-PQ), hybrid SQL + vector workloads, and serving infrastructure for retrieval-augmented generation (RAG).
- Distributed databases — sharding, replication, and the CAP-PACELC trade-offs that decide whether a multi-region system can stay responsive under failure.
Why study these four together?
Modern ML systems already are systems projects: a training pipeline touches every one of these layers at once. A compiler decision about operator fusion changes what the CPU pipeline sees; an OS scheduling policy changes how data loaders compete for I/O; a database choice between a row store and a vector store changes which optimizations the compiler can even apply. Treating these four threads as one research area is what makes it possible to reason about end-to-end performance honestly rather than locally.
Tools & Frameworks
Reading List
Compilers
- The Architecture of LLVM — Chris Lattner
- TVM: An Automated End-to-End Optimizing Compiler for Deep Learning — Chen et al., OSDI 2018
- MLIR: A Compiler Infrastructure for the End of Moore's Law — Lattner et al., 2020
- CompCert: A Formally Verified Optimizing C Compiler — Xavier Leroy, CACM 2009
Computer Architecture
- Computer Architecture: A Quantitative Approach — Hennessy & Patterson (6th ed.)
- In-Datacenter Performance Analysis of a Tensor Processing Unit — Jouppi et al., ISCA 2017
- Meltdown & Spectre — Lipp et al., USENIX Security / S&P 2018
- A Modern Primer on Processing in Memory — Mutlu et al.
Operating Systems
- Operating Systems: Three Easy Pieces — Remzi & Andrea Arpaci-Dusseau (free online)
- The Linux Kernel Documentation
- io_uring: A New Linux I/O Interface — Axboe, 2019
- KPTI: Kernel Page-Table Isolation — LWN, 2017
Databases
- Database Internals — Alex Petrov, O'Reilly 2019
- Designing Data-Intensive Applications — Martin Kleppmann
- The Seattle Report on Database Research — Bailis et al., 2019
- Efficient and Robust Approximate Nearest Neighbor Search Using HNSW Graphs — Malkov & Yashunin, 2016
- CMU 15-721 Advanced Database Systems (Andy Pavlo's lectures)